

Escaping Story Points with Right-sizing
Overcoming the Pain of Estimation

This article is part of Maarten’s summer guest writer series. During my summer break from writing, I want to shine a spotlight on great content written by others.
Remember that painful planning poker session where we’re stuck debating whether something is a “3” or a “5” or a “Small” not a “Large”?
What about that stakeholder who has asked how long something will take and all you’re able to tell them is that “it’s a 3-point item”, only for them to look at you confused because they can’t translate it to time.
We’ve all been in these kinds of estimation rabbit holes.
Story pointing, and to a lesser extent T-shirt sizing, have long been the bane of the agile world. A practice that everyone adopts, taught it as ‘training wheels’, yet even its creator deplores their use.
Here’s what Ron Jeffries had to say on Story Points in 2019:

The insistence of the agile community to continue to use them despite their proven inconsistency and uselessness for planning, highlights a professional protectionism where far too many practitioners have forgotten that this is about uncovering better ways. The latest (17th) State of Agile report sadly still has Velocity as the primary means of how teams measure success. What if there was a better way we could estimate and without the theatre or assigning points/t-shirt sizes to items?
You’re in luck. This is where right-sizing comes to the rescue…
What is Right-sizing?
Right-sizing isn't about reducing headcount to improve productivity in your organisation. When we ‘right-size’ work items we focus on making all our items no bigger than a certain size, using our historical data to inform us what this size is.
You may have come across similar approaches in the past, such as the “every item is a 1” or the even better Lunar Logic “no b*llshit estimation” cards:

Whilst this approach is similar, it still isn’t helpful when it comes to proactively managing the flow of work or when wanting to have collaborative conversations with those interested in when work will be completed. It is not an unfair question to ask when something is a “1” when it will likely finish. How long is too long for a 1 to be in-flight before we decide to take action?
This is where right-sizing comes into play. With right-sizing, we focus on making items no bigger than a certain size. However, we still acknowledge that variation in size is inevitable.
All you need to do before starting work on an item is have a conversation as a team as to whether you can—based on what you know right now—complete the item in n calendar days or less. n is derived from your historical data (85th percentile cycle time). Imagine if, as a team, we just decided together that if something takes more than 7 days, then it's too big. It's not based on data, but our collective opinion. When you do right-sizing, you decide on n-days or less based on data. This is what makes it empirical.
As a team, you would then proactively monitor the age of items in progress against your “right size” of items. Let’s look at an example team:
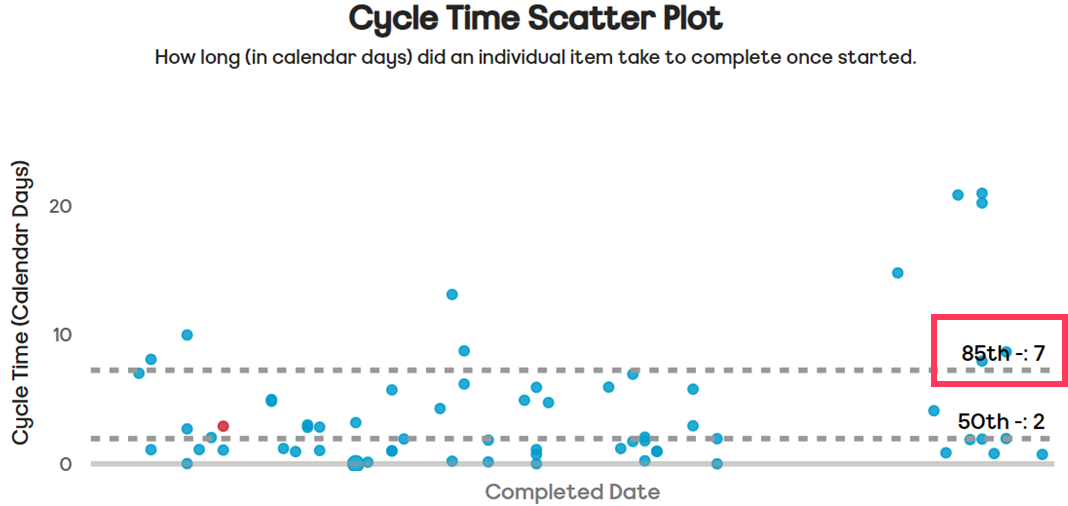
This is a scatter plot showing a team’s cycle time—the time (in calendar days) taken from when an item moves from ‘In Progress’ to ‘Done’.
Each ‘dot’ represents an individual item - the chart also plots the 50th and 85th percentile cycle time for all items. Teams can choose other percentiles if they wish but generally these are used as a starting point for them.
For this team, we can say that the ‘right size’ for their items is 7 days or less.
But it doesn’t stop there…
When it comes to estimation, the team would take the next highest priority item on their backlog.
As a team, they would ask — “Do we think this can be delivered within our 85th percentile cycle time?”
If “yes”, then let’s get started or mark it as ‘Ready’
(considering our current work-in-progress)If “no”, then let’s find out why/break it down till it is small enough
Once we start work on an item, we use Work Item Age as a leading indicator for flow:

Here we manage Work Item Age as part of your Daily Scrum/Standup. If it looks like it may exceed the 85th percentile (go above the upper line) — then swarm on it / break it down (in collaboration with your stakeholders).
This significantly simplifies estimation, going from a scale of 7 answers, to just two:

Adapted from Just use rightsizing, for goodness sake by John Coleman
Making it much simpler to estimate and break work down without the theatre of playing games with cards.
Why Should You Consider Right-sizing?
You should consider right-sizing if you’re in an environment where stakeholders want to know how long an item is likely to take (which is quite a lot of environments!). Similarly, you should also give it a go if you’re finding items are spilling over into the next sprint(s) and/or taking longer than expected.
To be clear, you do not need to immediately abandon story points/t-shirt sizing if you still have some affirmation for them or if there is a bureaucracy in place that can't be easily removed that requires you to produce these estimates. Often teams run the approaches in parallel before realising the points/t-shirt sizes aren’t adding any value.
Right-sizing Stories Example
Here is an example team that adopted it at Product Backlog Item (PBI)/User Story level. This team was using T-Shirt sizing as an approach, where they would estimate items with a t-shirt size of Small/Medium/Large. They asked for my help as they were not getting value in this as an estimation approach.
The team looked at their historical data for Cycle Time and settled on a right-size of 19 calendar days or less (their 85th percentile). In addition to this, they also added a Work Item Age field/automation to their board that would automatically update every day with the age of items in progress, so that the team could prioritise these items compared to their right-size.

After implementing this approach, the team saw significant benefits:
Cycle Time (85th percentile) decreased by 58% (from 19 to 9 days)
Throughput increased by 44% (from 54 to 96 items)

But What About Right-sizing Features/Epics?
Right-sizing doesn’t apply at just a PBI/User Story level. It can also be applied to higher backlog levels. Let’s say you want to break down an Epic/Feature into PBI’s/User Stories. You will want to know how long that Epic/Feature will take. We can use actually this data as part of our right-sizing approach.
In addition to looking at the percentiles for cycle time, we can also look at the percentiles for child item count:

Again a good starting point would be to use the 85th percentile, due to it providing enough coverage in our data whilst allowing for some outliers. The bigger the Feature/Epic, the more child items. The more child items the increased likelihood it takes longer. Taking longer leads to delays and ultimately impacts our predictability.
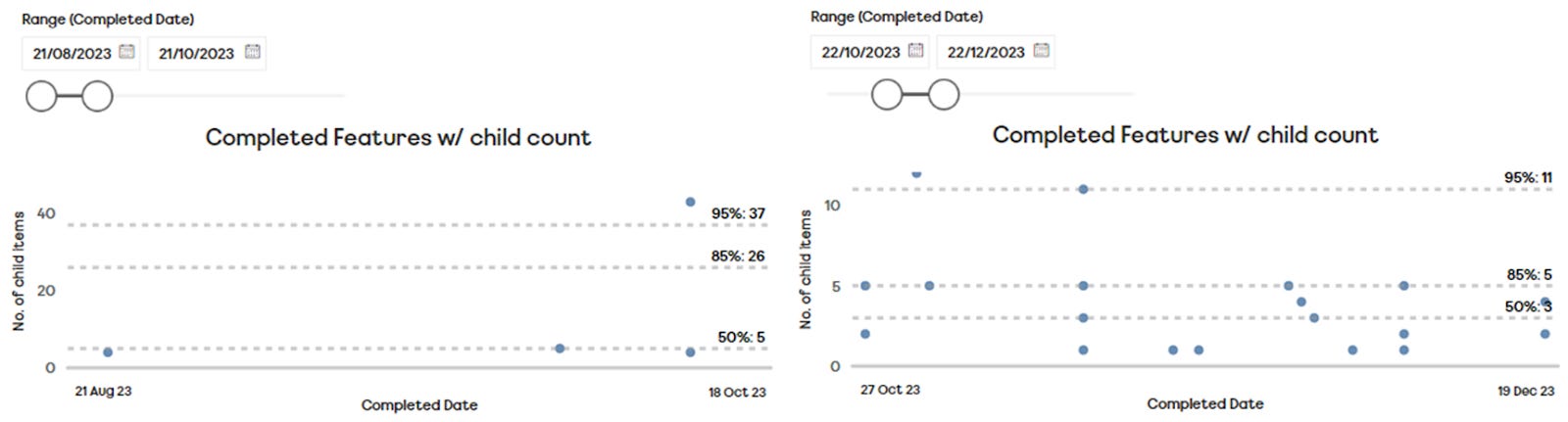
Taking this as as our right-size, we can see for this team that their right-size is 7 child items or less. This doesn’t mean every Feature has to be 7 child items, just that the vast majority should be no bigger than this. We can then plot this against our current Feature backlog to compare:

What we may want to do as a result of this data would be to break down those Features with the red flag against them, as they are bigger than our right-size. It may well be they’ve been broken down as much as they can be, which is why we use percentiles as there will always be an edge case that may go slightly over this value. If it was 34 child items then we’d know we’d lost our way! In any case the team is now aware of something they’ve broken down which may impact their predictability.
Right-sizing Features/Epics example
To show you that it ‘works’ let’s look at a team before and after right-sizing at Feature level. This team had 4 completed Features in the 3-month period we looked at for right-sizing their Features, with a right-size of 26 child items or less.

This team actually decided that they could deliver their work in smaller batches and settled on a right-size of 10 child items or less. Whilst this isn’t strictly ‘empirical’ in following what the data showed, it is using the data to inform their decision making. Call it data-led rather than data-driven! What they did following this was to review their backlog and break their features down so that they were still something that was deliverable/usable/consumable but that they were 10 child items or less. Embedding this as an approach led to the following:
Cycle Time (85th percentile) decreased by 25% (from 89 to 67 days)
Throughput increased by 375% (from 4 to 19 Features)
Batch-size reduced by 81% (from 26 to 5 child items)
What About When You Don’t Have Data?
Some of you may be reading this and coming to the conclusion of “this is great but what about if we don’t have the data?” which would be a fair observation. Whilst you almost certainly will have data already (unless you are a brand new team!) it may still be the case that this isn’t useful.
The answer to this is in fact pretty simple, collaborate and guess agree! You don’t need to overthink this and in most cases a 15-minute conversation can help you get to something. It will almost certainly be wrong however it gets you started and then, as you get ‘real’ data you’ll start to understand better what it should be. For example, if you’re a scrum team working in 2-week sprints, then a right-size of 14 days or less would be a good start. If you’re a team delivering Features and embedded in some type of quarterly planning process, then maybe a right-size of 90 days or less is a good start. You could take your current Feature backlog and ‘draw a line’ as to what feels right:

Just don’t worry about getting it perfect the first time, ultimately as you start to complete more Epics/Features with an aspirational right-size the data will lead you to what your right-size actually is.
Conclusion
Right-sizing is an approach to estimation that incorporates variation and data to make more informed decisions around breaking work down.
Contrary to other approaches (story points, t-shirt sizing) it doesn’t need the theatre of everyone picking random ‘values’ as a means to invoke conversation about breaking work down.
If you want to give it a try, all the tools I use are available free on my GitHub and work with many tools like Jira or Azure DevOps. They simply require Power BI and an API/Access Token.
One of the criticisms of right-sizing as an approach is that it doesn’t focus on the value of those items, instead on just improving their flow (speed/time to market, batch size, etc.). I’m not sure this is quite true, as the point is that being more predictable means you’re getting feedback sooner which inevitably will improve value delivery. If what you're doing is valuable, delivering it sooner, means you deliver more value. If you're delivering something that isn't valuable, delivering it sooner, means you discover it sooner and you waste less time on it you can use to deliver something valuable.
I’d also encourage readers to go further in their learning by watching this talk from Daniel Vacanti (also available as a written blog here), where he presents evidence of right-sizing outperforming (in the sense of value delivery) CD3 - cost of delay divided by duration (note: this is a proper version of WSJF, not the weird SAFe version!) by 182%.
To wrap-up, right-sizing is a fundamental practice that all teams need to consider if they care about agility, predictability and value delivery. It does not always even require data, with intent alone being enough. Finally, we can use it as an approach to finally start talking in a language that everyone in the organisation understands. Isn’t it a no-brainer?
What are your thoughts? Have you tried this approach? Let me know in the comments below!
 | A guest post by
|
Certainly compelling, Nick
In some environments, I've seen an obsession with Story Points grow into a spectacular distraction.
One effective approach is just to count "cards" – it all evens out in the end
But even that means we've forgotten to measure the most important thing:
Meaningful client behavior change outcomes.
Love the article ! Thanks for Posting it !!