

Better Than Post-Mortems: The Meta Post-Mortem
Focusing Beyond Singular Incidents

Last month, I couldn’t disarm my alarm after a short trip because Amazon Webservices (AWS) was down. The outage swept through many households. Some folks couldn’t even sleep because their smart beds stopped working.
Cloudflare recently crashed half the internet. Many funny pictures followed, like:

The one thing you can be sure of after massive outages like this: there will be a Post-Mortem.
The goal of a Post-Mortem isn’t to assign blame, but to understand why the issue happened and come up with concrete actions to prevent it from happening in the future.
The default starting point of a Post-Mortem: everyone makes mistakes. The fact mistakes can happen isn’t the problem. It’s about reducing the chance of the mistake happening again.
A good example of this is the GitLab incident in 2017 where a developer accidentally dropped the production database. The developer in question wasn’t fired. They did publish a post-mortem with mitigations on how they can prevent it from happening in the future.
Post-Mortems are incredibly valuable. But I’m going to argue many companies running Post-Mortems are missing out on something that can be even more valuable: Meta Post-Mortems.
The Benefit of Meta Post-Mortems
The problem with Post-Mortems is that they are usually isolated to the single incident you’ve just experienced.
Here is a simple visualization from Atlassian:

You’re trying to prevent that specific incident from happening again in the future by discovering the root causes that allowed it to happen.
Then you come up with mitigations to prevent from happening again in the future. But don’t be fooled: it all revolves around the original incident.
The problem with this approach, is that you’re unlikely to discover the deeper problems that allowed the incident to happen in the first place. Of course, we try to do that by keeping asking why, but let’s be honest many teams settle for surface-level mitigations.
Every production incident not only says something about the situation, but may also say something about your organization.
Imagine you’re in any any of the following situations:
One of the teams in the company frequently has post-mortems for incidents.
A company frequently has post-mortems across many different teams.
If either of these two situations apply, it’s a good idea to run a Meta Post-Mortem (MPM).
What’s a Meta Post-Mortem (MPM)?
In a Meta Post-Mortem, you’re not concerned with the specifics of the incidents. You’re simply using the past high-quality information of those incidents to potentially address systemic issues greater than any individual incident.
A Meta Post-Mortem focuses on uncovering the deeper problems and issues that allowed those production incidents to happen.
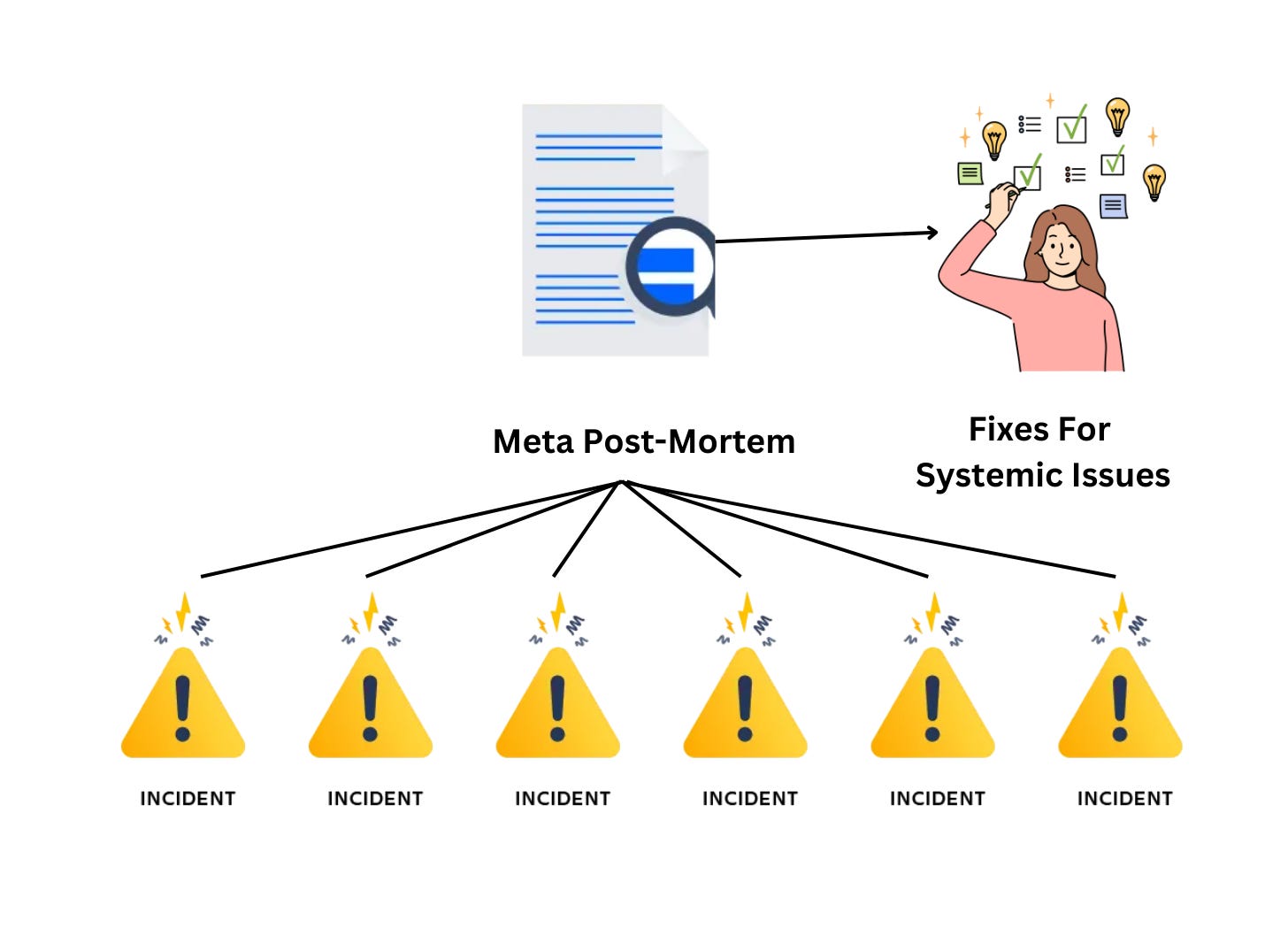
All those Post-Mortems are a treasure trove of high-quality content that potentially contain lots of systemic issues that are waiting to be addressed.
By looking through the lens of the Meta Post-Mortem (MPM), you can effectively look at the quality issues that you must address in your organization that go beyond any single team or single incident. You can even use AI to help speed up this process.
In short, if you see many Post-Mortems happening, it may be time to make it more reflective and meta, by running a Meta Post-Mortem. You can then uncovered deeper issues, like:
Teams working on too many different things at the same time
Too much technical debt
Not enough expertise present in the teams
Poor collaboration between teams
There are a gazillion possible reasons why you’re having too many production incidents. The beauty of the Meta Post-Mortem you can use it to look at all those incidents and go beyond the surface-level issues to discover the much deeper systemic issues that fester in your company.
In short, the next time you’re running yet another Post-Mortem, try to run a Meta Post-Mortem instead and make a much bigger impact beyond any single incident.
A single incident is a problem. Many incidents are a pattern and should trigger a Meta Post-Mortem.
I really like post-mortem analysis.And it can be useful not only in case of some incidents.In one of my team we have been using it regulary after every finished project about upgrades. We saw how many things we fixed project by project.It became a good practice for us.
Is this Meta Post-Mortems in fact a quest for finding a Holy Grail, no wait, in fact Real Root Cause, which means more system thinking (7+ why's and so on) included than only "hey, how can we make this particular one failure less likely to happen in the future"?