

Sprint Planning: Stop Wasting Time on Spreadsheet Capacity Micromanagement
Your Beautiful and Elaborate Sprint Planning Capacity Excel Spreadsheet IS the Problem

We've all seen those Scrum Teams that pull out an Excel sheet during Sprint Planning.
"Who is on holidays this Sprint?"
"Do you have any workshops or days with lots of meetings?"
“Do you have any work outside of the Sprint going on?”
The Scrum Master diligently records all the answers in his magnificent Excel spreadsheet. The Sprint Capacity Excel spreadsheet takes into account all of the following factors:
Team holidays
Unique expertise of team members for specific work
Meetings
Trainings
Time spent for personal learning
Unproductive hours
Non-Sprint work
Average velocity
This list of factors included in the spreadsheet isn’t even exhaustive. Using some splendid Excel wizardry, the capacity to do work in hours is converted back to a projected Velocity number that can be used during Sprint Planning.
Using the capacity-adjusted Velocity numbers during Sprint Planning slightly improves their situation, but the team still frequently overcommits to work and struggles to complete its commitments.
Why does this happen? Well, I’ve got news for you. The fact you believe a Sprint Capacity spreadsheet is the solution is exactly the problem!
Let’s explore our prickly capacity situation together.
Our Team Capacity per Sprint
Imagine a perfect world without distractions where everyone is 100% productive. Let’s agree that your team's capacity to work is 400 hours per Sprint.
We could visualize it as follows:

We all know this is a lie, and we’re talking about a Disney World situation that doesn’t exist. There are always interruptions and distractions. The Sprint doesn’t exist in a vacuum that completely disregards reality.
This is where our trusty old buddy, the Excel spreadsheet, comes to the rescue. The spreadsheet tries to paint a more realistic picture of our capacity by considering all the factors that may reduce your team’s capacity.
We could visualize the real capacity after our trusty friend the spreadsheet gives us a healthy dose of reality:

Our spreadsheet tells us we have 220 hours to do real work. Remember that this number isn’t even accurate because, unfortunately, we cannot predict the future.
All kinds of unplanned and unexpected distractions can and will happen, and you don’t know exactly how much time they will take, even if you try to take them into account with some average fudge factor.
Here are some things that can happen:
Emergency company meeting
Significant production issue that takes many days to fix
Sudden sickness or other reasons for unexpected absence
Another team urgently needs your help for something that’s more important than what you’re doing
Test environments suddenly being down for many days
This list of factors that reduce your capacity to do work is absolutely not exhaustive. There are many unexpected reasons you can’t see coming that will throw sand in your team's gears.
But let’s ignore the fact that you can’t even perfectly predict the capacity of your team to complete work. That isn’t even the real problem. The real problem is our inability to estimate accurately.
Let’s imagine this is the average velocity of our Scrum Team:
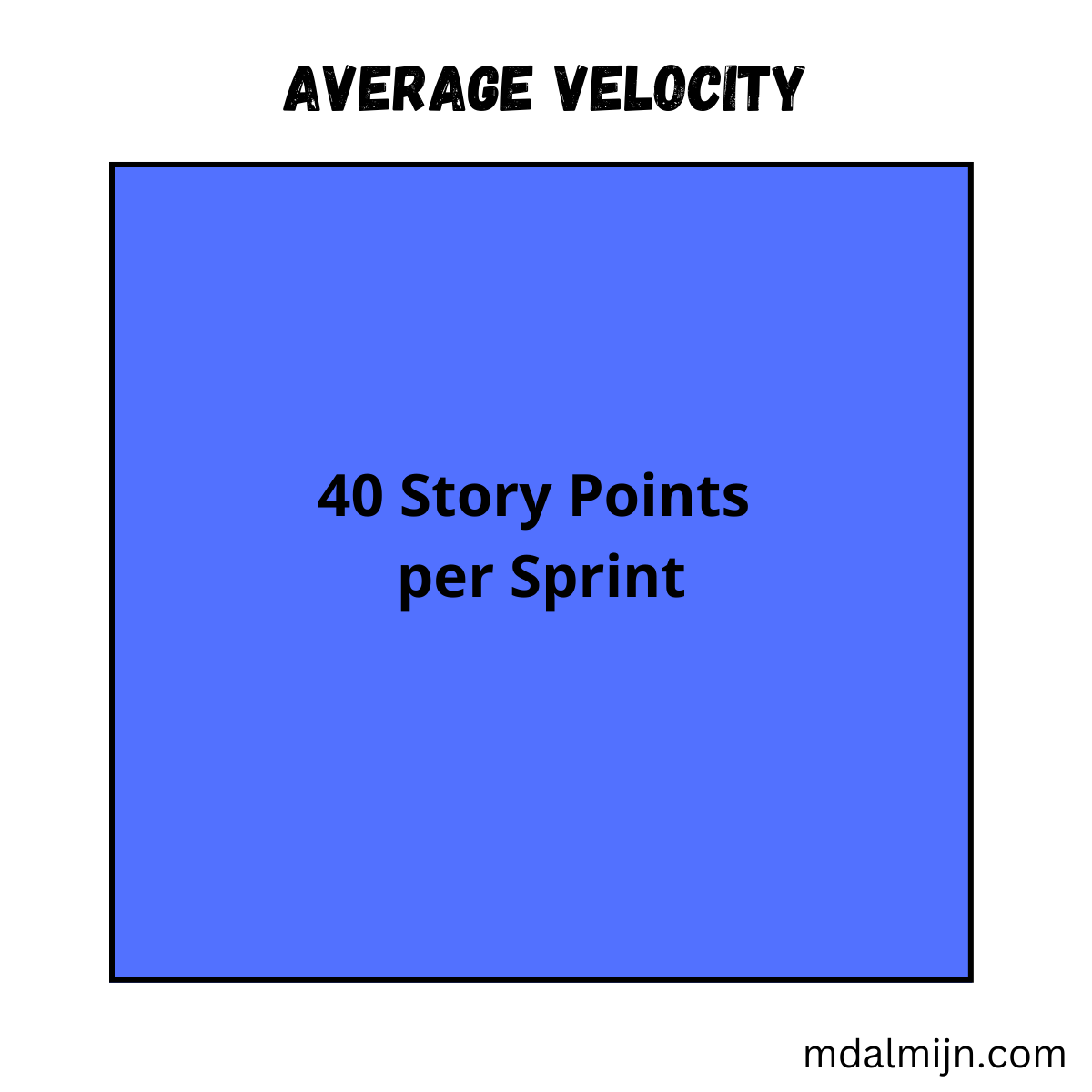
On average, our Scrum Team completes around 40 Story Points per Sprint. Awesome! That’s a reliable number we can use to plan our Sprint, right? Wrong!
The problem is that our estimates are guesses we make at a point in time we lack information to predict accurately. We can’t trust our estimates because they suffer from the Fog of Beforehand - what we can know before starting the work. What we can’t and don’t know before starting the work is what makes our estimates often explode and balloon out of control.
Let’s say we start our Sprint with those 40 Story Points. Here’s what’s actually going to happen, but we can’t know until after we’ve completed our Sprint:
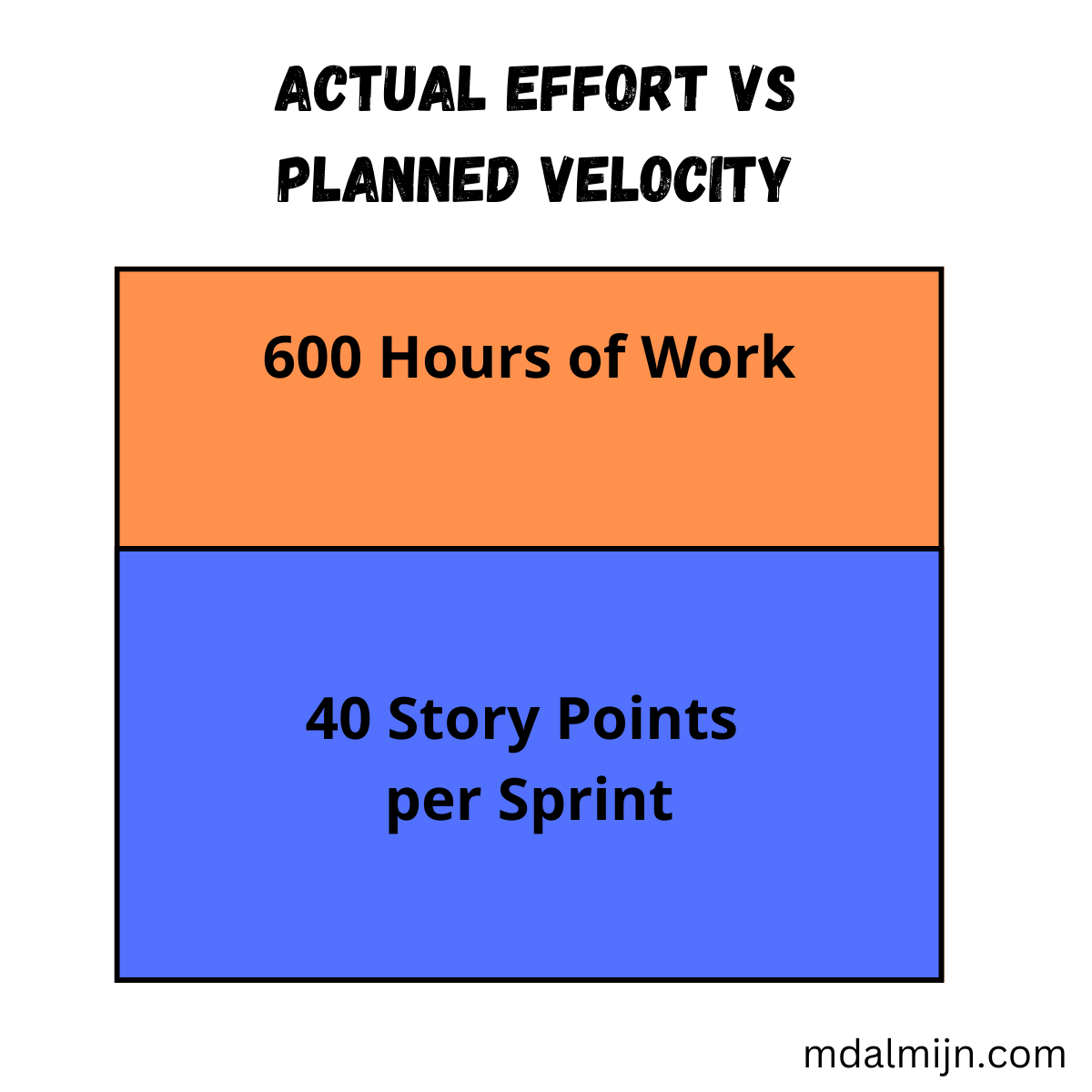
Congratulations: you’ve doomed your Sprint from the start. Despite committing to only 40 Story Points, we’ve actually committed to 600 hours of work. But we will never know that, until after we’ve started the work and are knee-deep in problems already.
Our Scrum Team has a theoretical perfect capacity of 400 hours to do work that we can never attain. Basically, we’ve doomed our Sprint from the start, even if we would be able to use our full theoretical maximum capacity.
During Sprint Planning, in essence, there’s a significant tension between our ability to predict our capacity and our ability to predict the effort of our work accurately:
Our inaccurate ability to predict our capacity
Our wildly inaccurate ability to estimate work
We’re less wrong with our ability to predict our capacity because there is a clear floor (0 hours) and a clear ceiling (400 hours). In the case of our work estimates, there is no obvious ceiling. Something we’ve estimated with 3 Story Points, could be 200 hours of work because we missed something crucial we couldn’t know before starting.
This brings us to the heart of the problem: capacity micro-management is the wrong way of approaching planning and indicates a profound misunderstanding of the real problem.
The real problem is the following: when doing complex work, no matter what you do, your estimates will be wrong.
Hence, it isn't your capacity that matters but your inability to match the right workload to your capacity. You can’t solve that problem even if you could perfectly predict your capacity.
We can visualize this problems as follows:
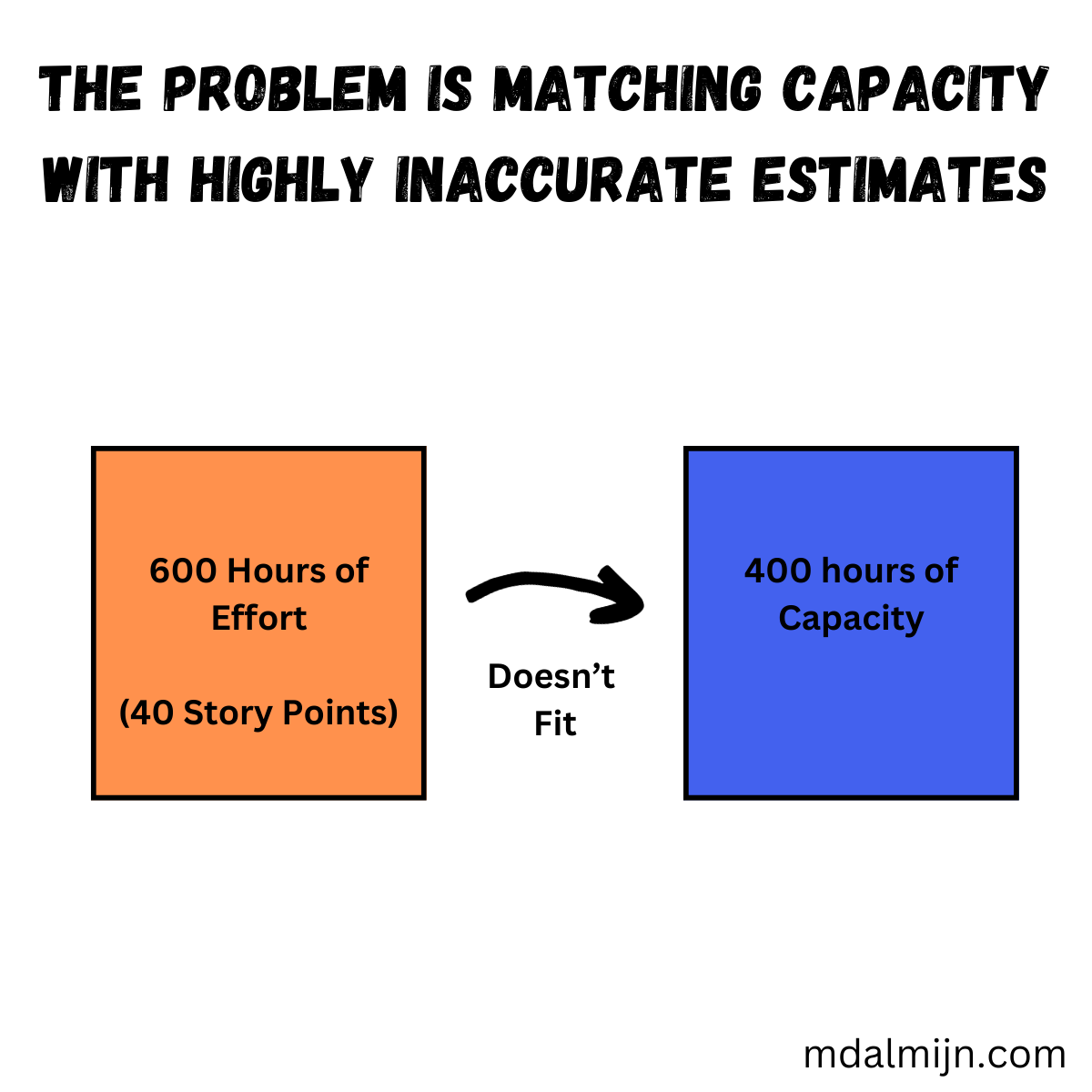
That begs the question: What should we do instead of trying to nail our capacity estimates?
Stop Trying to Perfect Your Ability to Predict
Trying to perfect the ability to predict is a fool’s errand. The more we try to prevent sucking at predicting, the more we will guarantee to suck at adapting.
When you do complex work, you can’t solve the problem of being unable to predict how much effort something represents perfectly. You can solve the inability to adapt.
The solution is simple: don’t push in work at the beginning of the Sprint. Pull in work gradually. Let the reality of the work and your actual capacity dictate how much work you pull in instead of letting the inaccuracy of your capacity and work estimates dictate how much work you push in.
How do you do that? It’s pretty simple:
Set a reasonable Sprint Goal.
The Sprint is flexible. Drag in more work as necessary and is possible based on the reality of your situation. Begin with humble plans that evolve as you encounter reality. No need for any fancy capacity calculations, because you’re not committing based on your Sprint’s capacity.
Instead of pushing in work based on capacity, pull in work based on the flow of work.
As long as you actively manage your flow, your available capacity will be taken into account. As long as you manage your flow and throughput, you will make the most progress possible. Even if you don't achieve your Sprint Goal in the end.
Adapt to reality at a time when you have the best information at your disposal about your situation instead of foolishly expecting your inability to predict your capacity and workload before Sprint even starts to save you from over-committing during Sprint Planning.
Don’t worry so much about the failure to predict because that’s going to happen anyway. Worry about the failure to adapt as reality unfolds and presents itself, as that’s where the biggest gains can be made.
"Adapt to reality at a time when you have the best information at your disposal about your situation" This!
I really liked the line - Instead of pushing in work based on capacity, pull in work based on the flow of work. !!